The model passed evaluation.
The accuracy metrics are solid.
The team ran the experiments.
The results were presented to leadership.
And it’s still not in production.
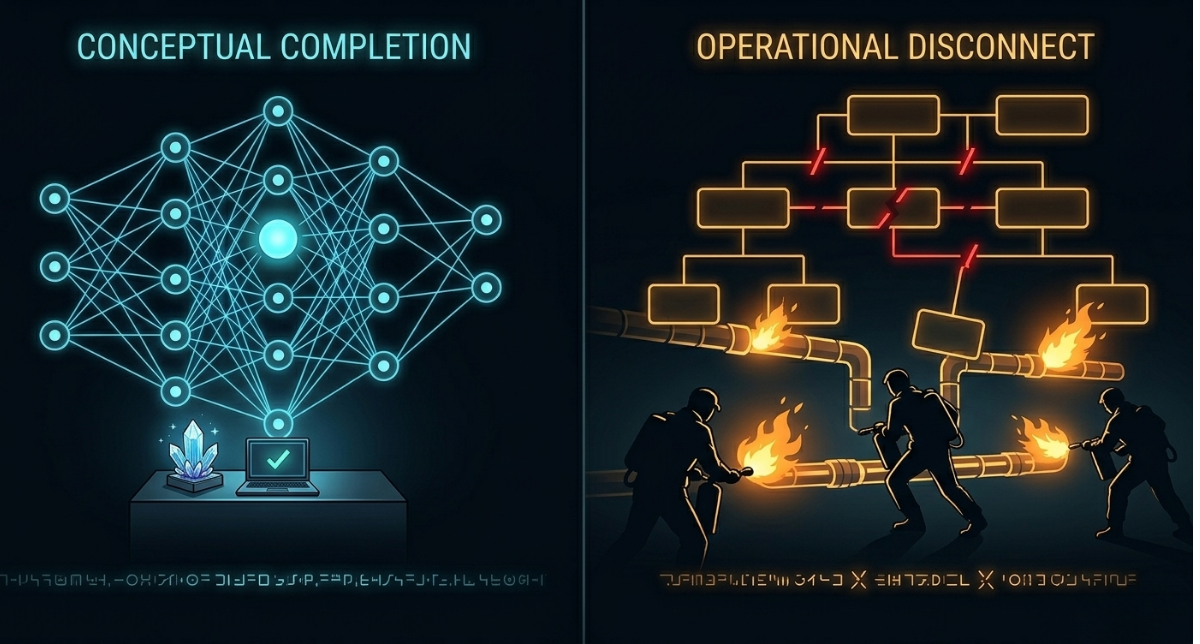
This is one of the most common — and most quietly expensive — failure patterns in AI delivery.
The technical work is done.
The organizational work was never started.
The model is only half the problem
Most AI delivery frameworks focus on the model.
Feature engineering.
Training pipelines.
Evaluation metrics.
Experiment tracking.
These are important.
But getting a model to production requires a second system to be ready — the organizational system.
- Who owns the production deployment?
- Which team handles incidents when the model behaves unexpectedly?
- Who approved the compliance review?
- What is the fallback if the model degrades?
- Who signs off before the model touches live data?
When those questions don’t have clear answers before the model is complete, deployment stalls.
Not because the model failed.
Because the organization was never set up to receive it.
The four organizational gaps that block deployment
1. Compliance and governance entered too late
Compliance is frequently treated as a final gate.
Teams complete the model work, then submit for review.
At that point, reviewers may require:
- additional documentation
- data lineage tracing
- retraining on approved datasets
- architectural changes
These requests arrive after the technical team considers the work finished.
The result is weeks or months of delay — not because the model was wrong, but because governance was never part of the workflow from the start.
This is the same pattern that creates late-stage rework across AI delivery:
2. No clear owner for the handoff
AI models cross organizational boundaries on the way to production.
Data engineering.
ML engineering.
Platform infrastructure.
DevOps or SRE.
The business team consuming the output.
Each group owns a layer.
But if no one owns the end-to-end production handoff, work stalls at every transition.
Teams wait for each other.
Tickets go unanswered.
Deployment steps are unclear.
This is how models sit in staging for weeks after evaluation is complete:
3. Production infrastructure was not prepared in parallel
Model development and infrastructure preparation often happen sequentially.
Teams finish the model, then begin preparing the serving environment.
This means:
- compute provisioning starts late
- monitoring systems are not configured
- APIs are not defined
- integration tests have not run
The model is ready.
The environment is not.
And the organization didn’t realize it until deployment began.
4. Monitoring and fallback are undefined
Production AI systems fail.
Models degrade.
Input distributions shift.
Downstream consumers depend on outputs that become unreliable.
Organizations that deploy without defined monitoring and fallback plans often discover the gap during the first incident — not before.
The absence of these definitions is not a technical oversight.
It is an organizational one.
No one was assigned to define them.
No one’s deadline depended on them.
So they didn’t get done.
Why this gap is invisible until it is expensive
Model completeness is easy to measure.
Evaluation metrics are concrete.
Training runs have timestamps.
Results can be presented in slides.
Organizational readiness is not measured the same way.
It doesn’t appear on a burndown chart.
It doesn’t generate a ticket.
It is only visible when deployment stalls.
By then, weeks of delay have already accumulated.
Leadership sees a completed model and a slipping date.
Teams feel the friction but can’t easily explain it.
The gap compounds silently.
This dynamic appears across AI delivery:
The cost of the last-mile stall
Every week a completed model sits outside production is a week of business value not captured.
In most AI initiatives, the expected ROI is not realized until the model operates on live inputs and produces outputs that influence decisions or automate workflows.
A model that stalls for two months at deployment has lost two months of that value — without appearing on any failure report.
This is the same quiet cost that compounds across delayed initiatives:
- The ROI Lost Each Month You Delay AI
- What AI Delays Really Cost the Business
- Your AI Budget Is Being Quietly Wasted
What “ready” actually means in practice
A model is production-ready when:
- a named owner exists for the production transition
- compliance and governance are already satisfied
- infrastructure is provisioned and tested
- monitoring thresholds and fallback behavior are defined
- the receiving team has confirmed operational requirements
None of these are technically complex.
All of them require organizational alignment — and that alignment must be established before the model finishes, not after.
High-performing AI teams treat production readiness as a parallel workstream, not a final checklist.
What high-performing teams do differently
The organizations that consistently ship AI initiatives share one visible characteristic:
They define the deployment contract before development begins.
That means:
- compliance is reviewed during design, not after evaluation
- infrastructure is provisioned as model development proceeds
- ownership of the production handoff is named explicitly
- monitoring is designed alongside the model
- the business team is aligned on what success looks like in production
This does not require more people.
It requires clearer sequencing and explicit accountability.
If your model work keeps finishing before your organization is ready
If AI initiatives consistently complete evaluation but stall before deployment…
If timelines stretch by weeks after the model is technically done…
If the gap between “model complete” and “live in production” feels disproportionate to the work…
The problem is not your engineering team.
It is the organizational readiness system that should have been running alongside them.
How to close the organizational gap
A focused Data & AI Delivery Efficiency Audit maps one AI initiative end-to-end — from project start through production deployment — and identifies:
- where organizational alignment breaks down
- which approval and governance steps arrive too late
- where ownership of the deployment handoff is unclear
- how much time is lost between model completion and production
- the specific changes that would close the gap fastest
The result is not a transformation program.
